Autoencoder and Variational Autoencoder
The success of machine learning algorithms generally depends on data representation, this is because different representations can entangle and hide the different explanatory factors of variation behind the data. Disentangled representations can be useful in tackling many downstream tasks and help improve robustness and generalizability of models. Representation learning has emerged to extract features from unlabeled data by training a neural network on a secondary, supervised learning task.
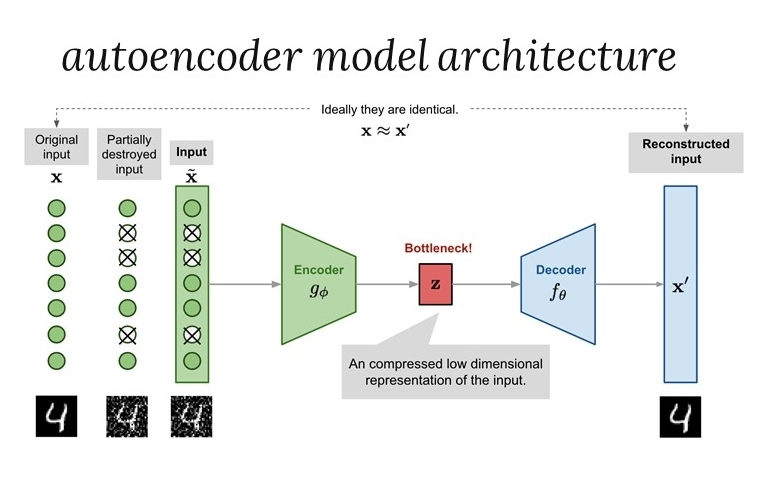
Autoencoders(AE) are an unsupervised learning technique in which we leverage neural networks for the task of representation learning. Specifically, we’ll design a neural network architecture such that we impose a bottleneck in the network which forces a compressed knowledge representation of the original input. If the input features were each independent of one another, this compression and subsequent reconstruction would be a very difficult task. However, if some sort of structure exists in the data (ie. correlations between input features), this structure can be learned and consequently leveraged when forcing the input through the network’s bottleneck.
A most simple autoencoder is a type of convolutional neural network (CNN) that converts a high-dimensional input into a low-dimensional one (i.e. a latent vector), and later reconstructs the original input with the highest quality possible. It consists of two connected CNNs. The first is an encoder network that accepts the original data as input, and returns a vector. This vector is then fed to the second CNN, the decoder that reconstructs the original data.
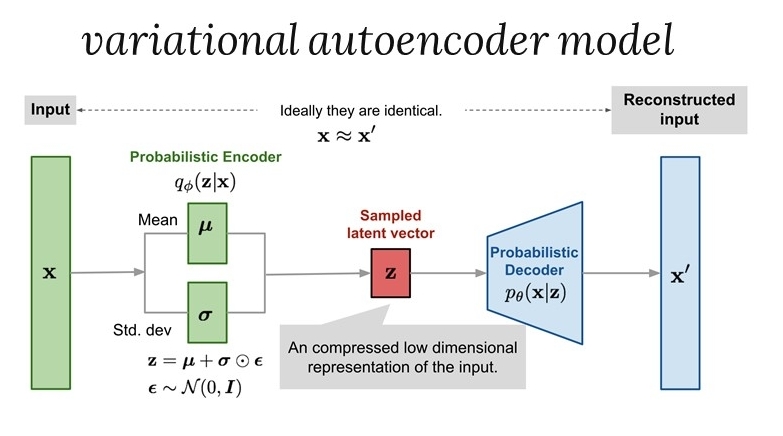
A variational autoencoder (VAE) provides a probabilistic manner for describing an observation in latent space. Thus, rather than building an encoder which outputs a single value to describe each latent state attribute, we’ll formulate our encoder to describe a probability distribution for each latent attribute. They have also been used to draw images, achieve state-of-the-art results in semi-supervised learning, as well as interpolate between sentences.
The VAE is also a deep generative model where one can simultaneously learn a decoder and an encoder from data. An attractive feature of the VAE is that while it estimates an implicit density model for a given dataset via the decoder, it also provides an amortized inference procedure for computing a latent representation via the encoder. While learning a generative model for data, the decoder is the key object of interest. However, when the goal is extracting useful features from data and learning a good representation, the encoder plays a more central role.