What to do with the data my boss gave me?
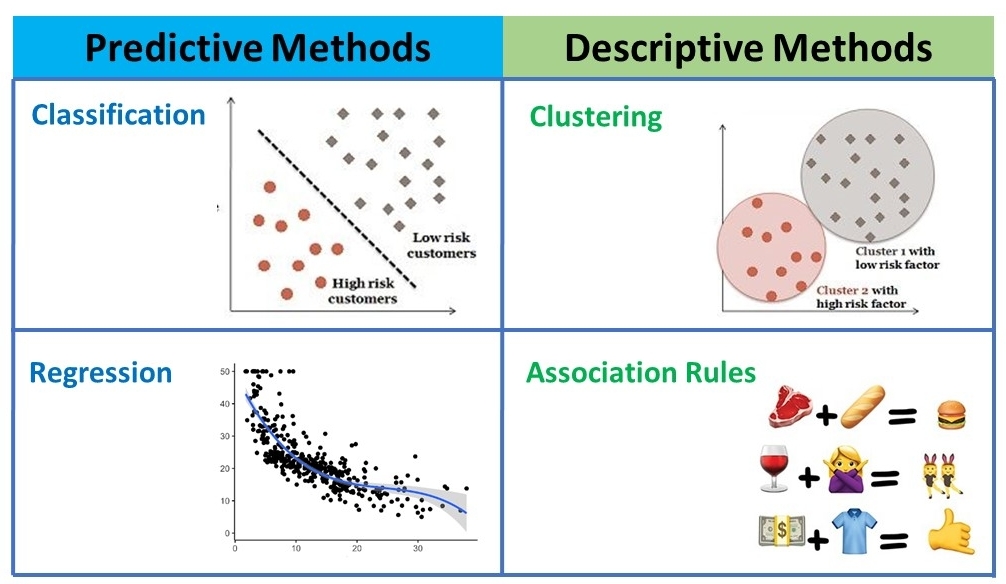
A classification model is using data’s similarities to map data into a specific labelled class. A clustering model involves grouping data with respect to their similarities. Clustering algorithms are mainly linear and nonlinear while classification consists of more algorithmic tools such as linear classifiers, neural networks, Kernel estimation, decision trees, XGBoost, and support vector machines.
A regression model is obtained from finding the association between the input x and output data y. A association rule is finding the association between individual items x in respect to the customers y. Estimated regression equation, in statistics, an equation constructed to model the relationship between dependent and independent variables. An association rule has two parts: an antecedent (if) and a consequent (then). An antecedent is an item found within the data. A consequent is an item found in combination with the antecedent.
When we know the label of the data, we can use the data and supervised learning to build predictive model to predict the properties of the new data coming in without labels. And the typical way is building a classifier or a regressor. When just data without any labels, we use the unsupervised learning method to either clustering the data into various groups or using association rule to analyze the relationship between various data. The measure of a regression model is the bias and variance. The strength of a given association rule is measured by two main parameters: support and confidence.
Machine learning model, deep learning model, transformer can be used to build classifier. Deep learning neural networks are an example of an algorithm that natively supports multi-output regression problems. Neural network models for multi-output regression tasks can be easily defined and evaluated using the Keras deep learning library. There are deep learning approaches for discovering kernels tailored to identifying clusters over sample data. Those neural network produces sample embeddings that are motivated by and are at least as expressive as spectral clustering. Association rules analysis is a technique to uncover how items are associated to each other and PyCaret is a simple way to understand it.